
In this paper, we study multi-label atomic activity recognition. Despite the notable progress in action recognition, it is still challenging to recognize atomic activities due to a deficiency in holistic understanding of both multiple road users’ motions and their contextual information. In this paper, we introduce Action-slot, a slot attention-based approach that learns visual action-centric representations, capturing both motion and contextual information. Our key idea is to design action slots that are capable of paying attention to regions where atomic activities occur, without the need for explicit perception guidance. To further enhance slot attention, we introduce a background slot that competes with action slots, aiding the training process in avoiding unnecessary focus on background regions devoid of activities. Yet, the imbalanced class distribution in the existing dataset hampers the assessment of rare activities. To address the limitation, we collect a synthetic dataset called TACO, which is four times larger than OATS and features a balanced distribution of atomic activities. To validate the effectiveness of our method, we conduct comprehensive experiments and ablation studies against various action recognition baselines. We also show that the performance of multi-label atomic activity recognition on real-world datasets can be improved by pretraining representations on TACO. We will release our source code and dataset.
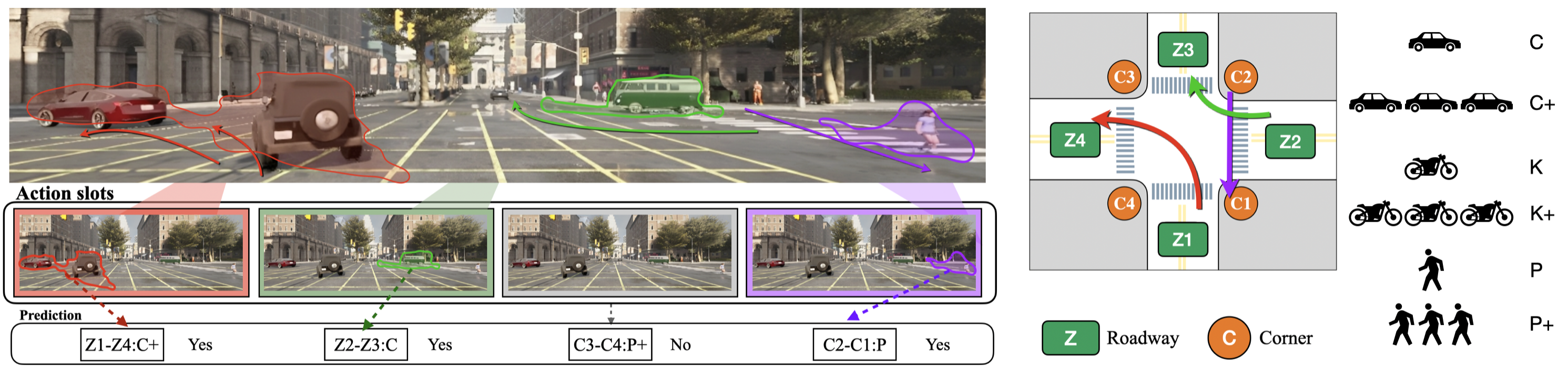
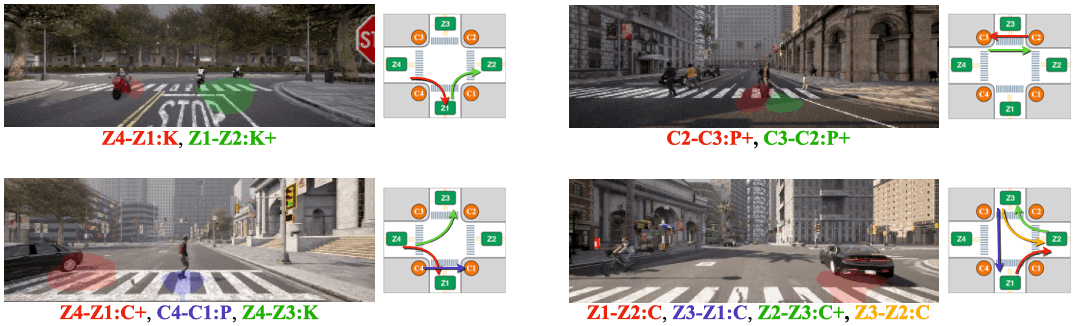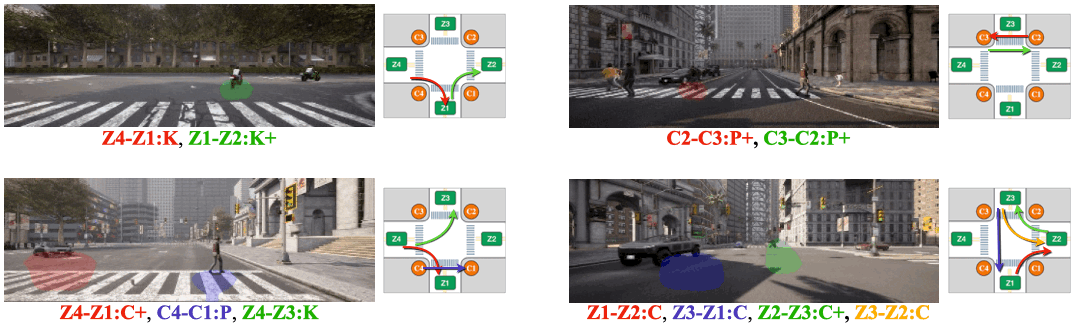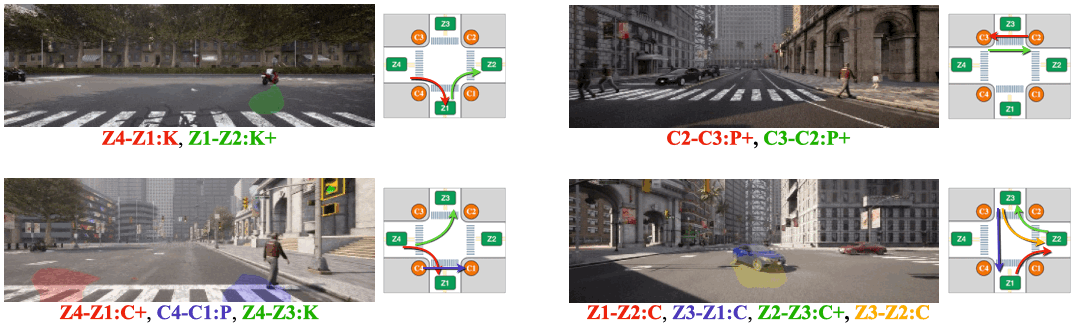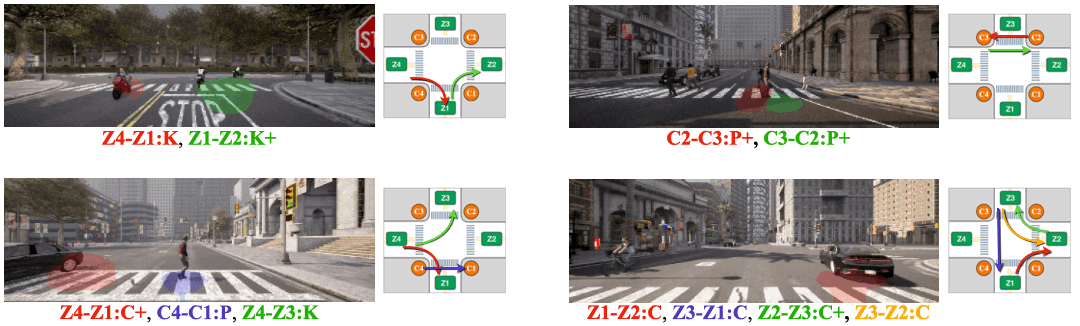
Illustration of the concept of multi-label atomic activity recognition and our proposed Action-slot. In the scene, three atomic activities are presented and depicted by colored arrows. For example, the red arrow represents the Z1-Z4: C+ atomic activity, indicating a group of vehicles turning left. Atomic activities are defined based on road user's type and their motion patterns grounded in the underlying road structure. We introduce Action-slot to learn visual action-centric representations that enable decomposing multiple atomic activities in videos. We demonstrate that our framework can effectively recognize multiple atomic activities via learned representations.
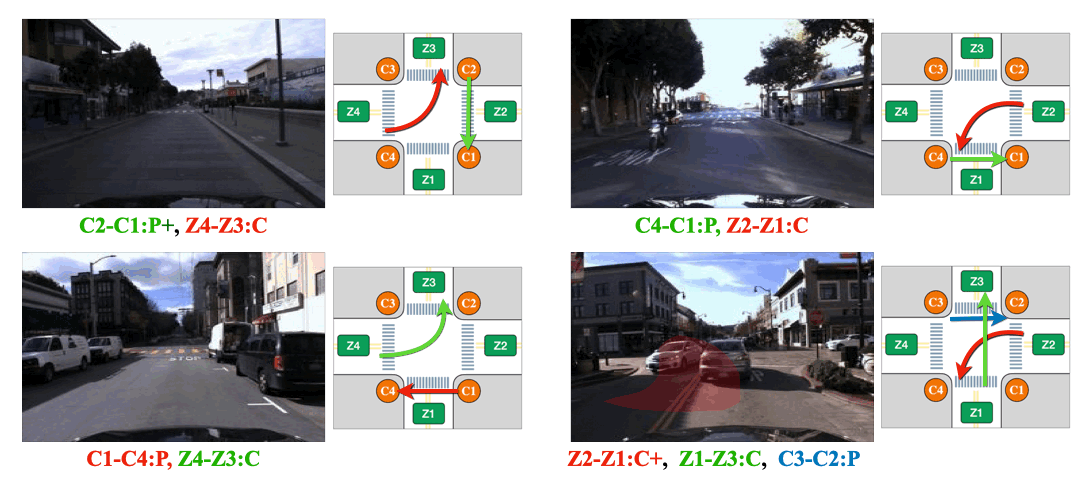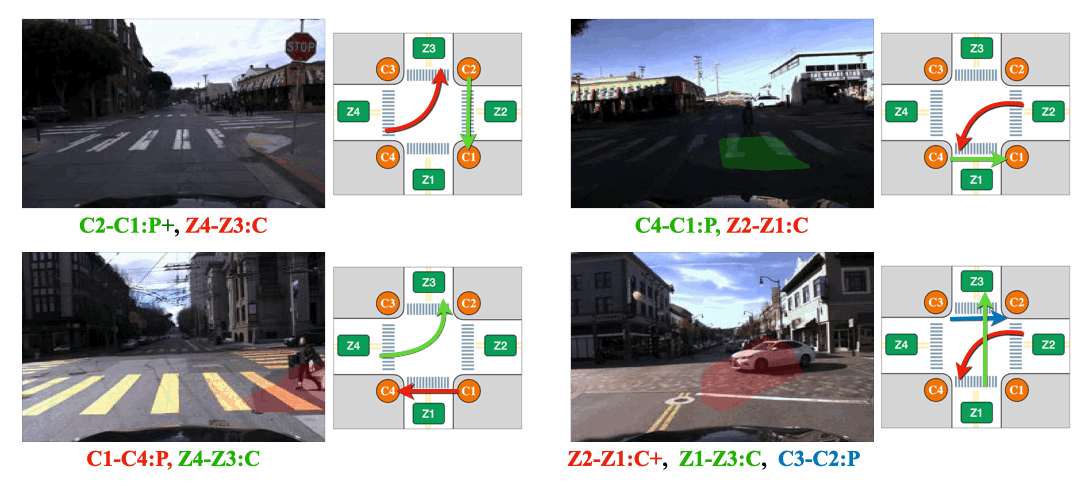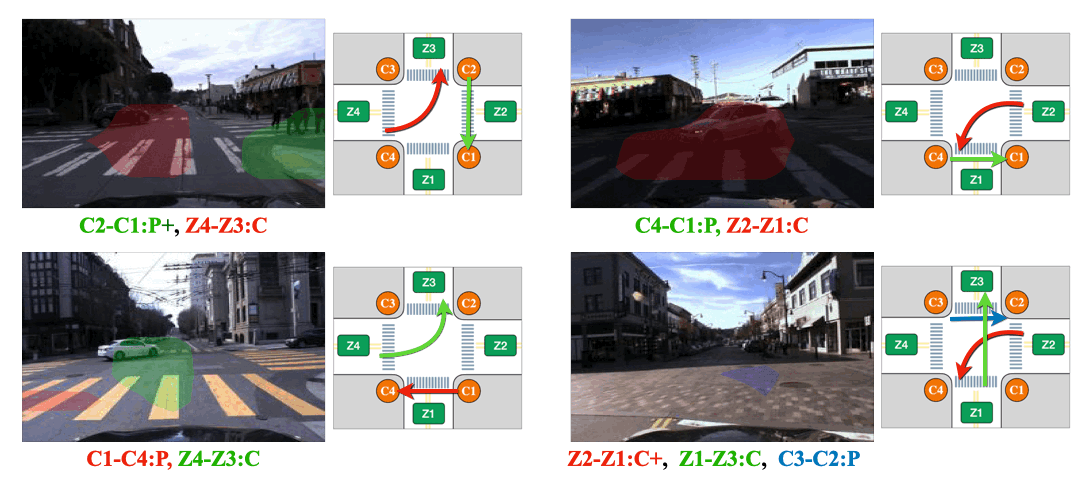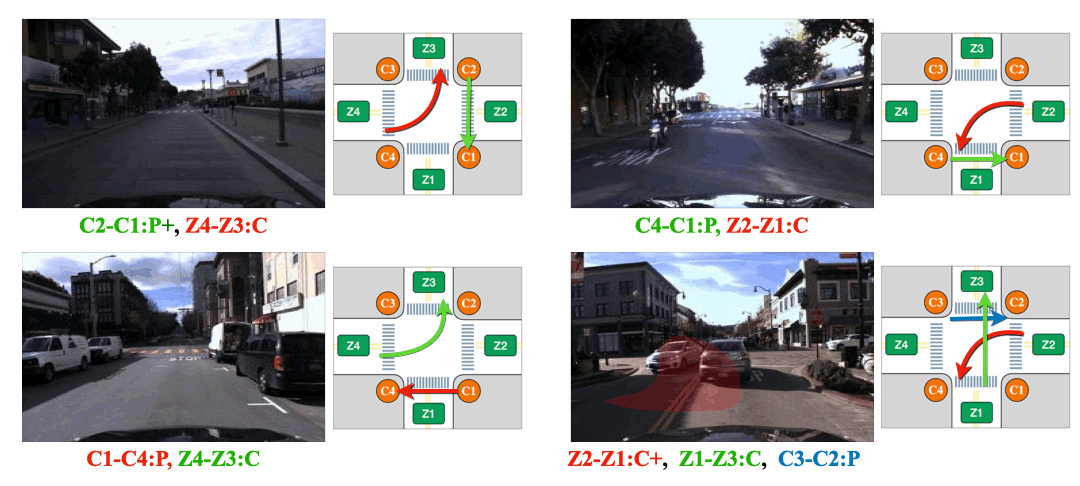
We visualize attention from action slots. Distinct colored masks represent the classes of atomic activitiy that the corresponding action slots pay attention to. Action-slot can localize atomic activities by training with weak action labels and without using any perception module (e.g., object detector).
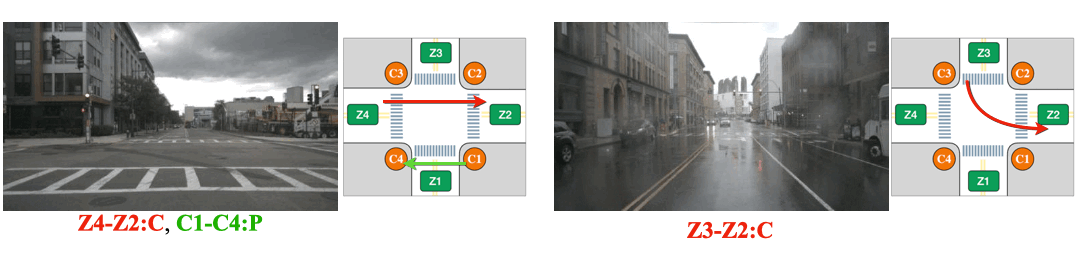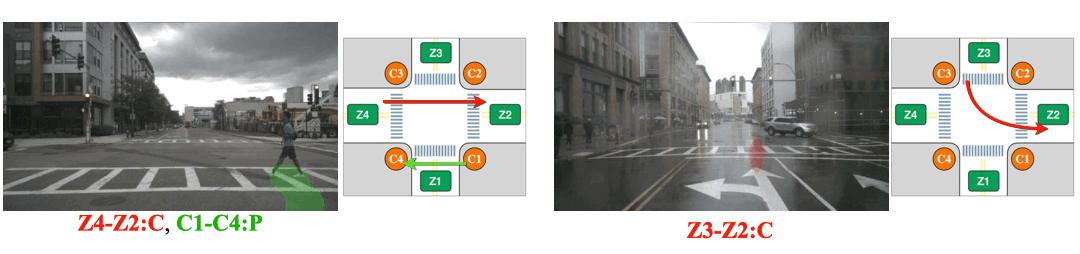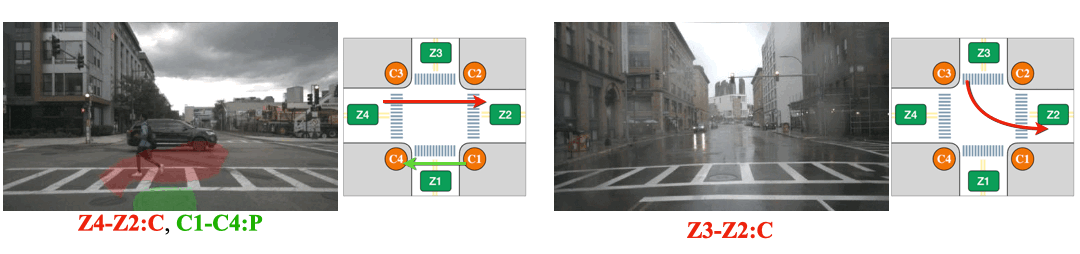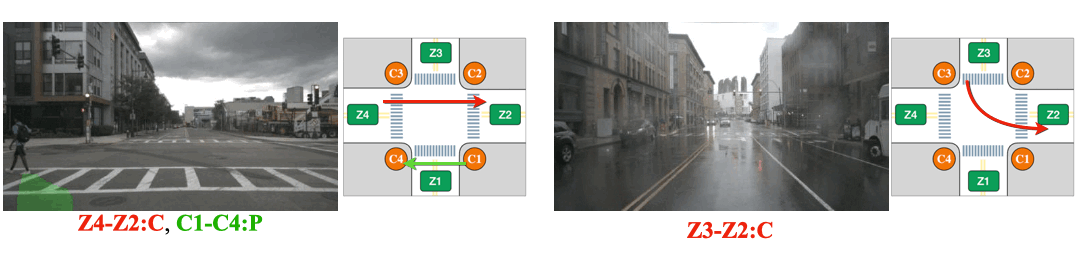
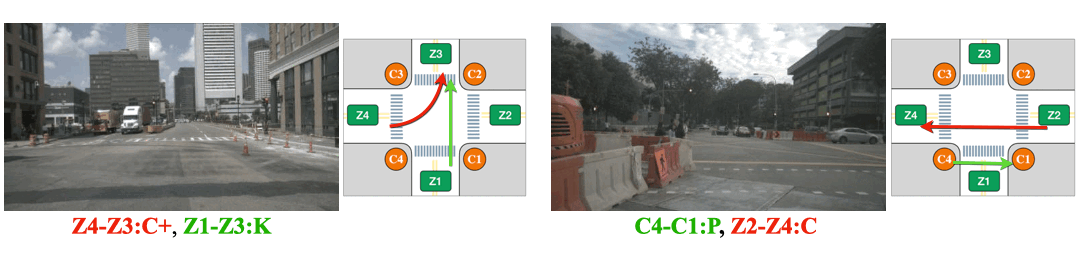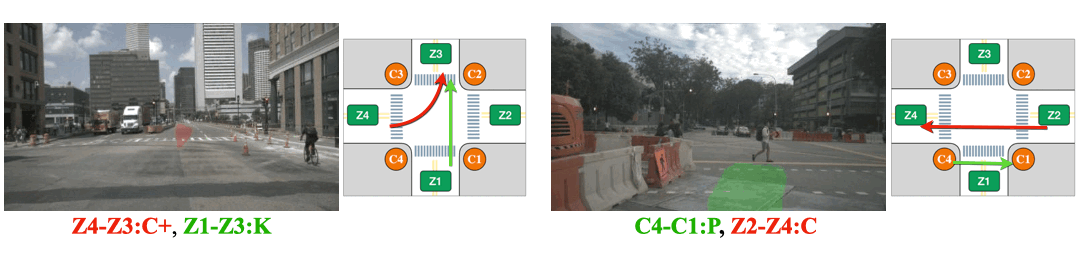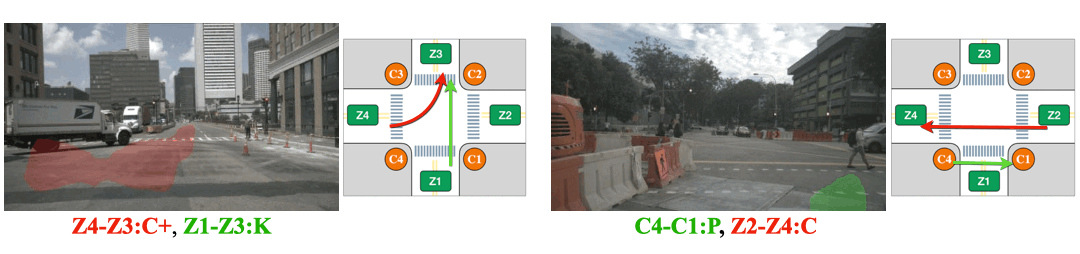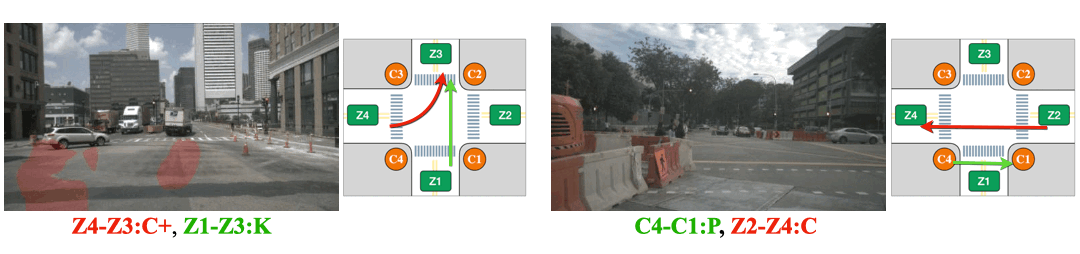
(Left) The intersection is partially occluded by the traffic cones. (Right) The Corner Z4 is entirely covered by the construction.
The pedestrian performs two actions consecutively. Action-slot can recognize the transition of actions.
We compare object instance mask guidance with Action-slot that is guided with L_{bg} and L_{neg} mentioned in Sec. 3.3. . We hpothesize that the object guidance can mislead the model because not all road users are involved in an activity. To verify it, we first create scenarios where presents many static pedestrians. Note that there is no atomic activity presented in the scenarios. Then we visualize the attention from the any slot that predicts false positive. The object-guided model is confused by the static road users and makes false positive predictions. While our Action-slot shows strong robustness in the scenarios.

[1] Agarwal et al., "Ordered Atomic Activity for Fine-grained Interactive Traffic Scenario Understanding". ICCV 2023
[2] Caesar et al., "nuscenes: A multimodal dataset for autonomous driving". CVPR 2020
@inproceedings{kung2023action,
title={Action-slot: Visual Action-centric Representations for Multi-label Atomic Activity Recognition in Traffic Scenes},
author={Kung, Chi-Hsi and Lu, Shu-Wei and Tsai, Yi-Hsuan and Chen, Yi-Ting},
journal={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}